İngiltere’de bulunan Cambridge Üniversitesi’nden araştırmacılar, sosyal, politik veya dini açıdan aşırılık yanlısı duruşlar benimseme ve ideoloji adına şiddeti destekleme eğilimli olan insanların “psikolojik parmak izini” temsil eden bir harita hazırladılar.
Radikal araştırmaları temel olarak, yaş, ırk ve cinsiyet gibi temel demografik bilgilere, bilişsel ve kişisel değerlendirmelerin eklenmesine dayanıyor.
Cambridge Üniversite’nden psikoloji uzmanları, demografi faktörlerinden 4 ila 15 kez daha güçlü bir model oluşturdular. Söz konusu model, aşırılık yanlısı eğilimleri olan insanın tanınmasında psikolojik parmak izini temsil ediyor.
Çalışmada, farklı ideolojilere karşı tutum ve duygularının gücünü belirlemek için 16 farklı anket kullanılarak, 334 kişi üzerinde bir dizi takip testi gerçekleştirildi. Dün “Philosophical Transformation of Royal Society” dergisinde yayınlanan model, aşırılık eğilimleri olan bir kişinin işleyen hafızasının zayıf olduğu ve “bilişsel stratejilerinin” daha yavaş olduğu, dürtüsellik ve heyecan verici haber arama eğilimlerine ek olarak, şekil ve renk benzeri değişken uyarıcıların bilinçsizce işlenmesi gibi, kişilik özellikleri ile zihinsel özelliklerin bir karışımını içeriyor.
Bilim adamları ayrıca, aşırılıkçı eğilimin, daha liberal zihinlerdeki hızlı ve hassas olmayan “bilişsel stratejiler” ile karşılaştırıldığında, bilinç dışı yavaş ve doğru karar verme anlamına gelen “bilişsel dikkate” bağlı olduğunu tespit ettiler.
Ayrıca, radikal eğilimleri olan insanların beyinlerinin algısal kanıtları işlemekte daha yavaş olduğunu, ancak tepkiler açısından daha dürtüsel davrandıklarını keşfettiler.
Bu araştırma hala ilk aşamalarında olsa da, bilim adamları bulgularının siyasi ve dini konularda aşırılığa karşı savunmasız kişileri daha iyi tespit etmeye yardımcı olabileceğine inanıyorlar.
Cambridge Üniversitesi Psikoloji Bölümü’nden araştırmanın başyazarı Lior Zmegrod, araştırmanın yayınlanması ile eş zamanlı olarak üniversitenin internet sitesinde yayınlanan raporda “Zihinsel ele alıştaki karmaşık zorluklar, insanları bilinçsizce dünya için daha net ve daha belirli açıklamalar sunan aşırılıkçı doktrinlere yönlendirebilir. Bu, onları ideolojik ve otoriter ideolojilerin zehirli şekillerine karşı savunmasız hale getiriyor” ifadelerine yer verdi.
Zmegrod “İdeolojik düşüncenin şekillendirilmesinde bilişsel işlevlerin oynadığı rolle ilgileniyoruz ve bu bağlamda çalışmamızın yararlı olduğunu iddia ediyoruz” dedi.
Bilim ‘radikal zihnin’ psikolojik parmak izini belirliyor

Cambridge Üniversitesi
Bilim ‘radikal zihnin’ psikolojik parmak izini belirliyor
Cambridge Üniversitesi


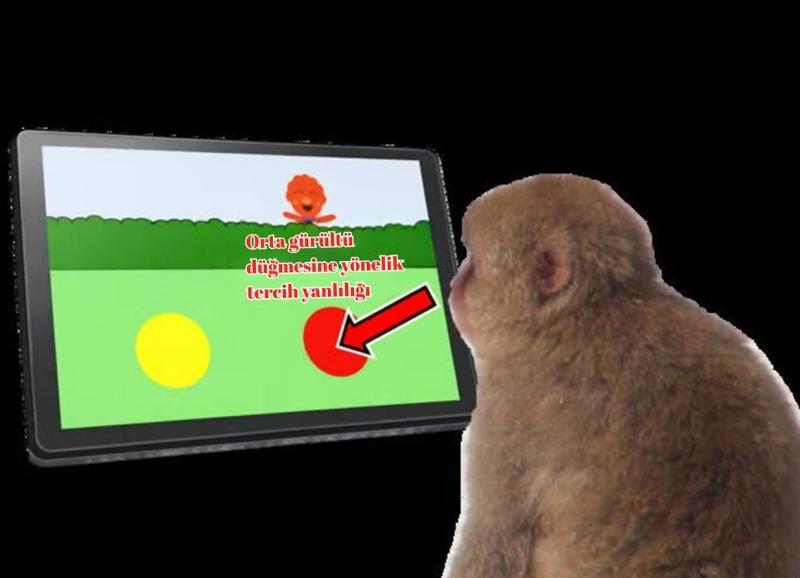 Video oyunu oynayan maymun (KyotoU/Sakumi İki)
Video oyunu oynayan maymun (KyotoU/Sakumi İki)
لم تشترك بعد
انشئ حساباً خاصاً بك لتحصل على أخبار مخصصة لك ولتتمتع بخاصية حفظ المقالات وتتلقى نشراتنا البريدية المتنوعة
