Bilim insanları, Mars'ın uyduları Phobos ve Deimos'un bir zamanlar Kızıl Gezegen'in yörüngesinde dönen daha büyük bir uydunun parçalanmasıyla oluştuğunu düşünüyor.
Gökbilimciler daha önce Mars'ın iki uydusunun biçimsiz şekilleri ve pürüzlü yüzeylerini açıklamak için birçok teori ortaya attı. Bunlardan biri, söz konusu uyduların Kızıl Gezegen'in çekim kuvvetine kapılan göktaşları olduğu ileri sürmüştü. Ancak sonraki araştırmalar bu uyduların, göktaşlarına kıyasla daha düzenli yörüngelere sahip olduğunu gösterince bu fikir kanıtlanamamıştı.
Şimdiyse İsviçre Federal Teknoloji Enstitüsü'nden gezegenbilimci Amirhossein Bagheri ve meslektaşları yeni bir çözüm önerisi sundu. Araştırmacılar geçmişte Mars yörüngesinde bulunan büyük bir uydunun parçalanarak bu iki cismi oluşturduğunu, parçalarından bir kısmınınsa gezegene yağdığını öne sürdü.
Araştırmacılar bu cisimlerin nasıl evrimleştiğini anlamak için NASA'nın şu anda Kızıl Gezegen'de bulunan InSight uzay aracının elde ettiği sismik veriler de dahil olmak üzere Mars, Phobos ve Deimos'la ilgili son verileri analiz etti.
Bunun sonucunda uyduların yörüngelerinin 1 ila 2,7 milyar yıl önce kesişmiş olabileceği saptandı. Araştırmacılar buradan hareketle iki uydunun atasının, şiddetli bir çarpışma nedeniyle parçalanan daha büyük bir uydu olduğu sonucuna vardı.
Bagheri, "Mars'ın eskiden daha büyük bir uydusu olduğu ve ona doğru yaklaşan cisimlerden biriyle çarpıştığı fikrini, çok heyecan verici ve şaşırtıcı buluyorum" diye konuştu.
Bu çarpışmanın yarattığı enkazın, Mars yüzeyine düşmüş olabileceği tahmin ediliyor. Bagheri, sözlerini şöyle sürdürüyor:
"Mars'ın yüzeyi çarpışmaların meydana getirdiği kraterlerle dolu. Bunların çoğu da büyük uydunun parçalanması için hesapladığımız zaman aralığı içinde oluşmuş."
Araştırmacılar ayrıca Deimos'un yörüngesi nedeniyle Mars'tan yavaşça uzaklaştığını, Phobos'un ise gezegene yaklaştığını keşfetti. Phobos'un gelecekte Mars'la çarpışacağı ya da 39 milyon yıl içinde gezegenin çekim kuvveti yüzünden parçalanacağı tahmin ediliyor.
Bulgularını saygın bilim dergisi Nature'da yayımlayan Bagheri, ileri araştırmalarla, teorize ettikleri bu büyük uyduya dair daha fazla bilgi edinebileceklerini aktardı.
Araştırmacı, Japonya Uzay Ajansı'nın Phobos'tan örnekler toplamayı hedeflediği Marsian Moons Exploration (Mars Aylarının Keşfi) görevinin de yeni veriler sağlayacağını umuyor.
Independent Türkçe, Space
Yeni Mars araştırmasından çarpıcı sonuç: "Geçmişteki büyük uydusu parçalandı, enkazı gezegene yağdı"

Phobos ve Deimos, isimlerini Yunan mitolojisinin savaş tanrısı Ares'in çocukları olan iki kötü karakterden alıyor (NASA)
Yeni Mars araştırmasından çarpıcı sonuç: "Geçmişteki büyük uydusu parçalandı, enkazı gezegene yağdı"
Phobos ve Deimos, isimlerini Yunan mitolojisinin savaş tanrısı Ares'in çocukları olan iki kötü karakterden alıyor (NASA)


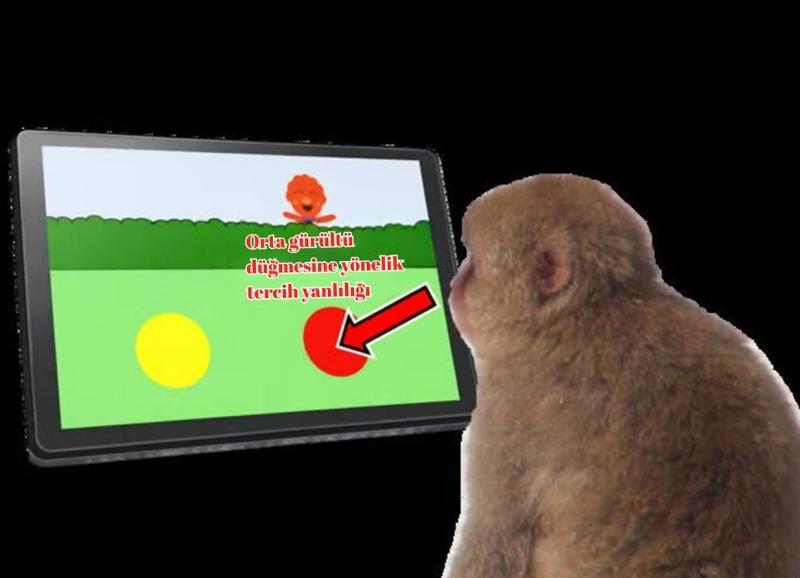 Video oyunu oynayan maymun (KyotoU/Sakumi İki)
Video oyunu oynayan maymun (KyotoU/Sakumi İki)
لم تشترك بعد
انشئ حساباً خاصاً بك لتحصل على أخبار مخصصة لك ولتتمتع بخاصية حفظ المقالات وتتلقى نشراتنا البريدية المتنوعة
