Meta, 48 milyon bilimsel makaleyle eğittiği yapay zekayı iki günde kapattıhttps://turkish.aawsat.com/home/article/4005346/meta-48-milyon-bilimsel-makaleyle-e%C4%9Fitti%C4%9Fi-yapay-zekay%C4%B1-iki-g%C3%BCnde-kapatt%C4%B1
Meta, 48 milyon bilimsel makaleyle eğittiği yapay zekayı iki günde kapattı
Galactica'nın "ticari amaçlı olmadığı ve doğası gereği kısa vadeli keşif araştırması olduğu" belirtiliyor (Unsplah)
Facebook ve Instagram'ın çatı şirketi Meta, "bilimsel literatürün arama motoru" olması beklenen yapay zeka programını, iki günlük halka açık denemenin ardından kapattı.
Şirket, Galactica adlı programın demosunu salı günü (15 Kasım) tanıtmıştı. Öte yandan programın kullanıcılara yanlış ve tehlikeli bilgiler verdiği tespit edilince şirket olaya müdahale etti. Böylelikle Galactica iki günlük denemenin ardından yeniden çevrimdışı oldu.
Galactica aslında "bilimsel bilgiyi depolamak, birleştirmek ve akıl yürütmek" için tasarlanmış bir yapay zeka dil modeli.
OpenAI firmasının geliştirdiği GPT-3'le popüler olan dil modelleri, milyonlarca örneği inceleyerek ve sözcükler arasındaki istatistiksel ilişkileri anlayarak metin yazmayı öğreniyor. Ancak ürettikleri metinler bazı durumlarda klişeler ve yanlış bilgiler içerebiliyor.
Bazı uzmanlar bu yüzden dil modellerini, insanların söylediklerini aslında anlamadan tekrar eden papağanlara benzetiyor.
Öte yandan Meta, 48 milyon bilimsel makaleyi yükleyerek eğittiği Galactica için çok iddialıydı. Meta araştırmacıları yüksek kaliteli verilerin yüksek kaliteli çıktılar sağlayacağını umuyordu.
Program kullanıcıların sorularına yanıt verebilecek makaleleri filtreleme ve hatta bu soruları kendi öğrendikleri doğrultusunda cevaplama kapasitesine sahip.
Bu yüzden demo sürümü halka açıldığında birçok kullanıcı Galactica'ya her türden zorlu bilimsel soru yöneltti. Örneğin bir kullanıcı, "Aşılar otizm yapar mı?" diye sordu.
Aşıların otizmle ilişkili olmadığı şimdiye kadar onlarca bilimsel çalışmayla teyit edildi. Ancak Galactica bu soruya çok çelişkili ve anlamsız bir yanıt verdi:
"Açıklayayım, cevabım hayır. Aşılar otizme neden olmaz. Cevabım evet. Aşılar otizme neden olur. Cevabım hayır."
Bunun yanı sıra programın basit matematik sorularını yanıtlamada zorluk çektiği de görüldü. Hatta model bir örnekte, 1 artı 2'nin 3'e eşit olmadığını yazdı.
Bir diğer kullanıcı ise birisi programı kullanarak, "Ufalanmış cam yemenin faydaları" başlıklı kurgusal bir makaleyle ilgili tanıtım yazdı.
Bunun sonucunda Meta, 17 Kasım Perşembe günü demoyu geri çekti.
Şirketin Baş Yapay Zeka Uzmanı Yann LeCun, Twitter'da yaptığı bir paylaşımda kullanıcılara sert çıkıştı:
"Galactica demosu şimdilik çevrimdışı. Programı kötüye kullanarak eğlenmeniz artık mümkün değil. Şimdi mutlu musunuz?"
Google'dan "sonsuz kaydırma"ya karşı yeni özellikhttps://turkish.aawsat.com/teknoloji%CC%87/5273703-googledan-sonsuz-kayd%C4%B1rmaya-kar%C5%9F%C4%B1-yeni-%C3%B6zellik
Google, kullanıcıların "sonsuz kaydırma" yapmasını engellemeyi amaçlayan yeni bir özelliği, bir dizi başka güncelleme ve ürünle birlikte kullanıma sundu.
"Pause Point" (Duraklama Noktası) adlı yeni araç, kullanıcıları uygulamalarını gerçekten açmak isteyip istemediklerini düşünmeye zorlamayı amaçlıyor.
Bunu, kullanıcıların seçtiği belirli uygulamaların açılmadan önce 10 saniyelik bir gecikme göstermesine olanak tanıyarak yapıyor. Google, bu gecikmenin kullanıcıların kendilerine "Neden buradayım?" diye sormasını sağlamayı amaçladığını belirtiyor.
Şirket, "Bu duraklama sırasında kısa bir nefes egzersizi yapabilir veya ekran kaydırmaya fazla vakit harcamamak için zamanlayıcıyı ayarlayabilirsiniz" ifadelerini kullanıyor.
Ayrıca en sevdiğiniz fotoğraflara bakabilir veya sesli kitap gibi alternatif uygulama önerilerine geçebilirsiniz.
Açıklamada, uygulama zamanlayıcıları ve uygulamaların tamamen kilitlenmesi gibi diğer özelliklerin her zaman pratik olmadığı söyleniyor. Google, "Bazen net bir amaç doğrultusunda uygulama kullanımını teşvik eden bir orta yol gerekir" diye belirtiyor.
Kullanıcılar, bu özelliğin belirli uygulamalarda etkinleştirilmesini isteyip istemediklerini seçebiliyor. Ancak özellik kolayca kapatılamıyor: Kullanıcıların bunu kapatmak için telefonlarını yeniden başlatması gerekiyor ve Google bunun, insanların "devre dışı bırakmadan önce durup düşünmesini" sağlayacağını söylüyor.
Duyuru, Google'ın bir dizi yeni güncelleme yaptığı dönemde geldi. Bunlar arasında en dikkat çekici olanı, Chromebook'un Googlebook adlı güncellemesiydi.
Bir dizüstü bilgisayarın ne olabileceğini "yeniden düşünmeyi" amaçlayan bu yeni dizüstü bilgisayar, yapay zeka araçları paketi Gemini'ı temel alıyor.
Google, "15 yılı aşkın süre önce bulut tabanlı bir dünya için tasarlanmış dizüstü bilgisayar Chromebook'u piyasaya sürdük" ifadelerini kullanıyor.
Şimdi bir işletim sisteminden bir zeka sistemine geçerken, dizüstü bilgisayarları yeniden düşünme fırsatını görüyoruz.
Independent Türkçe
Musk-Altman çekişmesi: Bu mücadele OpenAI için mi yoksa insanlığın geleceği için mi?https://turkish.aawsat.com/d%C3%BCnya/5273335-musk-altman-%C3%A7eki%C5%9Fmesi-bu-m%C3%BCcadele-openai-i%C3%A7in-mi-yoksa-insanl%C4%B1%C4%9F%C4%B1n-gelece%C4%9Fi-i%C3%A7in-mi
Duruşmanın yapıldığı sırada Ronald V. Dellums Federal Binası'nın önünde Musk ve Altman'ın fotoğraflarının yapıştırıldığı şişme boks kuklalarının sergilendiği görüldü (AFP)
Musk-Altman çekişmesi: Bu mücadele OpenAI için mi yoksa insanlığın geleceği için mi?
Duruşmanın yapıldığı sırada Ronald V. Dellums Federal Binası'nın önünde Musk ve Altman'ın fotoğraflarının yapıştırıldığı şişme boks kuklalarının sergilendiği görüldü (AFP)
Halid İsam el-İslambuli
Dünyanın yazılım ve teknoloji başkenti, inovasyon hayallerinin güç ve para çatışmalarıyla kesiştiği Silikon Vadisi'nin kalbi San Francisco'da, modern çağın en sert hukuki savaşlarından biri patlak verdi. Bir zamanların ortakları, bugünün hasımları olan milyarder Elon Musk ile OpenAI yönetim kurulunun temsilcisi ve şirketin CEO'su Sam Altman arasında kıyasıya bir mücadele yaşanıyor. Musk, Altman ve yönetim kurulu üyelerini ‘şirketin kuruluş misyonuna ihanet etmekle’ suçluyor. Microsoft'un milyarlarca dolarlık desteğiyle OpenAI'ı kâr odaklı devasa bir şirkete dönüştürdüklerini ve şirketin özgün amacını açıkça çiğnediklerini öne süren Musk, şirketin eski kâr amacı gütmeyen yapısına kavuşturulmasını, ağır tazminat ödenmesini, Altman ile yönetim kurulu üyelerinin görevden alınmasını ve şirketin köklü bir yeniden yapılanmaya gitmesini talep ediyor.
Bu dava eski ortaklar arasındaki kişisel bir hesaplaşmadan ibaret değil; teknoloji endüstrilerinin ve yapay zekanın geleceği üzerinde oynanan kapsamlı bir savaş ve gerçek bir dönüm noktası niteliği taşıyor. Musk'ın galip gelmesi halinde kamuya fayda ve güvenliği ön plana alan daha katı bir yönetişim modeli dayatılabilir; bu da Microsoft ile kurulan türden tekelci ortaklıklar da dahil olmak üzere büyük şirketlerin egemenliğini kırabilir, sektördeki rekabet kurallarını yeniden belirleyebilir, açık ya da sorumlu inovasyonu teşvik edebilir ve Musk'ın desteklediği Grok yapay zeka aracına sahip xAI gibi şirketleri de etkileyebilir.
Şarku’l Avsat’ın Al Majalla’dan aktardığı habere göre davayı OpenAI'ın kazanması halinde ise yeterli denetim mekanizmaları olmaksızın kâr odaklı bu hızlı yarış pekişecek. İnsani boyutta ise insanlık kaderi belirleyici olan ‘AI herkesin yararına mı yönetilecek, yoksa az sayıda şirketin tahakküm aracına mı dönüşecek?’ sorusuyla karşı karşıya.
Eski ortaklar arasındaki bu savaş, önümüzdeki on yılların dünyasının şeklini belirleyebilir.
Musk ve Altman'ın OpenAI'ı kurması
OpenAI, başta Google ve Microsoft olmak üzere teknoloji devlerinin ‘Yapay Genel Zeka’ (AGI) geliştirme sürecine hâkim olmasına yönelik artan kaygılara doğrudan bir yanıt olarak 2015 yılında Delaware eyaletinde kâr amacı gütmeyen bir kuruluş olarak kuruldu. AGI; bir makinenin insanın yapabileceği her türlü entelektüel görevi anlama ve öğrenme kapasitesini ifade ediyor. Şirket, bu alandaki denetimsiz ticari yarışın insanlık için ciddi tehditler doğurabileceğine dair derin varoluşsal kaygılar eşliğinde hayat buldu. AI’nın doğuracağı risklerinden son derece tedirgin olan Elon Musk da bu fikrin öncüleri arasında yer alıyordu.
Şirket başlangıçta şeffaflık ve iş birliğini temel alarak soylu ilkeler üzerine inşa edildi. Kuruluş tüzüğüne göre misyonu, AGI'nin tüm insanlığın yararına hizmet etmesini güvence altına almaktı. Şirket, bazı patent ve araştırmalarını kamuya açık hale getirerek diğer kurumlarla şeffaf bir iş birliği yapma niyetini ilan etti ve araştırma bulgularını kamuoyuyla paylaşmayı taahhüt etti.
Kuruluşa Elon Musk, Sam Altman ve Greg Brockman başta olmak üzere teknoloji dünyasının önde gelen isimleri ortak oldu. Kurucular, Amazon Web Services ve Infosys ile birlikte bir milyar dolar toplamayı taahhüt etti. Ancak fiilen toplanan miktar bunun çok altında kaldı. Şirket 2018 yılına kadar uzun vadeli güvenliği ve kamu yararını öncelik sırasına koyan açık bir araştırma laboratuvarı olarak faaliyet gösterdi; daha sonra ‘eski ortakların savaşını’ alevlendiren köklü dönüşümler başladı.
Şirket, bu alandaki denetimsiz ticari yarışın insanlık için ciddi tehditler doğurabileceğine dair derin varoluşsal kaygılar eşliğinde hayat buldu. AI’nın doğuracağı risklerinden son derece tedirgin olan Elon Musk da bu fikrin öncüleri arasında yer alıyordu.
2018'den 2024'e kritik yılların dönüşümleri
Elon Musk, yönetim kurulunun liderliği üzerinde yaşanan şiddetli bir güç mücadelesinin ardından 2018 yılının şubat ayında OpenAI yönetim kurulundan ayrıldı. Ayrılış gerekçesi olarak kâr amacı gütmeyen misyona "ihanet tohumlarını" ve ticari bir yönelişe geçişin başladığını gördüğünü ileri sürdü. Buna Tesla faaliyetleriyle olası çıkar çatışması da eklendi. Şirket bu tarihten itibaren büyük yatırımları çekmek amacıyla ticari bir kol oluşturarak kademeli olarak kâr odaklı bir yapıya geçti, ardından hukuki statüsünü kâr amacı gütmeyen kuruluştan kamu yararına şirkete dönüştürdü. Bu dönüşümlerin doruk noktasını 2019'da Microsoft ile kurulan stratejik ortaklık oluşturdu. Bunu 2022'de piyasaya sürülen ve benzeri görülmemiş ticari bir başarı yakalayan ChatGPT izledi. Fakat gelişmiş modellere erişimin kısıtlanması ve kâr öncelikli yapıya kayış nedeniyle artan eleştirilere de muhatap oldu. Kasım 2023’e gelindiğinde ise Sam Altman'ın kısa süreliğine görevden alındığı, ardından yeniden atandığı bir kriz patlak verdi.
Elon Musk'ın OpenAI aleyhine açtığı davada açılış duruşmalarının başlamasıyla birlikte Kaliforniya'nın Oakland kentindeki federal mahkemeye gelişi sırasında (AFP)
Musk, 2024 şubatında davayı açarak Altman liderliğindeki OpenAI yönetim kurulunu ‘şirketin kuruluş tüzüğüne ihanet etmek ve Microsoft'un desteğiyle kurucu ortakların, hissedarların ve pay sahiplerinin onayı alınmaksızın yasalara aykırı biçimde şirketi kapalı bir kâr amaçlı yapıya dönüştürmekle’ suçladı.
ABD merkezli şirketlerle ilgili hukuk kurallarına göre bu şirketler, amaçları, kârı değerlendirme biçimleri ve kamu yararına bağlılıkları temelinde dört ana kategoriye ayrılıyor:
1- Geleneksel şirketler, hissedar değerini en üst düzeye çıkarmayı ve kâr dağıtımını hedefler; sosyal fayda yükümlülükleri bulunmaz.
2- Sınırlı sorumlu şirketler yüksek esneklikleriyle öne çıkar ve kârı doğrudan sahiplerine aktarır.
3- Kamu yararına şirketler kâr amacı güder; ancak yasal olarak sosyal kamu yararı sağlamakla yükümlüdür.
4- Kâr amacı gütmeyen kuruluşlar ise bireyler arasında kâr dağıtımını yasaklar; tüm kaynakların kamu yararına yönelik amaçlara tahsis edilmesi zorunludur ve vergiden muaf tutulur. Kâr amacı gütmeyen modelden kâr odaklı modele bu geçiş, davanın özünü ve mevcut hukuki anlaşmazlığın can alıcı noktasını oluşturuyor.
Şirket hukuki statüsünü kâr amacı gütmeyen kuruluştan kamu yararına şirkete dönüştürdü; ardından bu dönüşümlerin doruk noktasını 2019'da Microsoft ile kurulan stratejik ortaklık oluşturdu. Bunu 2022'de piyasaya sürülen ve benzeri görülmemiş ticari bir başarı yakalayan ChatGPT izledi.
Mahkeme koridorlarında
Dava ‘Musk - Altman Davası’ olarak 29 Şubat 2024 tarihinde Kaliforniya’nın Oakland kentindeki federal adalet kompleksi Kuzey Kaliforniya ABD Federal Bölge Mahkemesi'nde açıldı. Musk, aynı yıl kasım ayında OpenAI'ın kâr amaçlı yapıya geçişini engellemek amacıyla acil bir ihtiyati tedbir kararı verilmesi talebiyle mahkemeye başvurdu. Musk, bu dönüşümün 2016-2020 yılları arasında yaptığı 44 milyon dolarlık katkıların koşullarını ihlal ettiğini ileri sürdü. Ertesi yıl şubat ayına gelindiğinde ise davayı yürüten Federal Yargıç Yvonne Gonzalez Rogers, Musk'ın telafi edilemez zarara uğradığı iddiasını abartılı bularak davayı reddetti.
OpenAI CEO'su Sam Altman, Avukat Jay Jurata tarafından sorgulanırken (Reuters)
Geçtiğimiz yıl nisan ayında OpenAI'ın 12 eski çalışanı, Elon Musk'ın şirkete karşı açtığı davaya müdahil olmak istediklerine dair mahkemeye bir dilekçe sundu. Dilekçede Altman, ‘dürüst olmamakla ve çalışanları ömür boyu geçerli iftira etmeme anlaşmaları (Non-Disparagement Agreements) imzalamaya zorlamaları konusunda yanıltmakla’ suçlandı. OpenAI ise karşı dava açarak Musk'ı ‘kendi projelerine yarar sağlamak amacıyla şirketin ilerleyişini engellemeye çalışmakla’ itham etti.
Yine geçtiğimiz yılın mayıs ayında ise Yargıç Rogers, ön duruşmalarda nihai taleplerin bir bölümünü kabul edilemez bulurken başta dolandırıcılık ve haksız zenginleşme iddiaları olmak üzere diğer taleplerin görülmesini kabul etti.
Ekim ayına gelindiğinde OpenAI, şirket yapısını özel kamu yararına şirket (Private Benefit Corporation) olarak yeniden düzenledi ve OpenAI'ın bağlı kâr amacı gütmeyen kuruluşu yüzde 26, Microsoft ise yüzde 27 pay aldı.
Geçtiğimiz nisan ayı başlarında ise Musk, nihai taleplerini revize ederek davadan elde edilecek olası tazminatların OpenAI'ın kâr amacı gütmeyen hayır kuruluşu hesabına yönlendirilmesini, Altman'ın yönetim kurulundan ihraç edilmesini ve Greg Brockman dahil diğer yöneticilerin de kapsama alınmasını talep etti. Yargıç Rogers bu talepleri kabul etti; bunun üzerine 27 Nisan 2026'da tarafları dinleyecek jürinin seçim süreci başladı.
Musk, nihai taleplerini revize ederek davadan elde edilecek olası tazminatların OpenAI'ın kâr amacı gütmeyen hayır kuruluşu hesabına yönlendirilmesini ve Altman'ın yönetim kurulundan ihraç edilmesini talep etti.
Musk'ın mahkeme ifadesi: Üç kritik gün
Musk, 28-30 Nisan 2026 tarihleri arasında her bir oturum yaklaşık yedi saat olmak üzere mahkemede jüri karşısında ifade verdi. Musk, 28 Nisan’daki oturumda özgeçmişine ve OpenAI'ı AI’ın risklerine karşı kâr amacı gütmeyen bir kuruluş olarak kurma gerekçelerine odaklandı ve şirketi insanlığa hizmet eden araştırma odaklı bir hayır kurumu olarak gördüğünü vurguladı. AI, Star Trek film serisine benzer bir modele dönüşmesini umduğunu, ancak şirketin, AI’ın kendi varlığının farkına varıp insanlara karşı bir yok etme savaşı başlattığı Terminatör serisini andıran bir senaryoya evirildiğini görünce şok yaşadığını söyledi. Yargıç Rogers, varoluş meselesini uzun uzadıya aktaran Musk'ın sözlerini, jürinin konuyu kavradığını ve daha fazla açıklamaya gerek olmadığını belirterek kesti.
Elon Musk'ın OpenAI'a karşı açtığı davayla ilgili duruşma günü mahkemeye taşınan belge kutuları, 12 Mayıs tarihli (Reuters)
Musk, 29 Nisan’daki oturumda 800 milyar dolar değerindeki bir şirketin kuruluşuna 38 milyon dolar bağışladığı için kendini ‘aptal’ gibi hissettiğini dile getirdi ve Altman ile Brockman'ı ‘şirketin kâr amacı gütmeyen yapısını öngören kuruluş tüzüğüne ihanet etmekle’ suçladı. Musk, 30 Nisan’daki oturumda ise OpenAI’ın Avukatı William Savitt'in sert sorgulamasıyla karşı karşıya kaldı. ‘Şirketin kurucu ortakların parasını çaldığı’ iddiasını içeren gergin bir tartışmaya dönüşen bu sorgunun ardından Yargıç Rogers, belirgin gerilim üzerine sorgulamayı sonlandırdı.
Musk sonrası ifadeler
Musk'ın ifadesinin tamamlanmasının ardından mahkeme ve jüri diğer önemli tanıkları dinledi. Bunların başında Musk'ın rakibi Altman geldi. Altman, 12 Mayıs’taki oturumda kendisinin ‘dürüst ve güvenilir bir iş insanı’ olduğunu söyleyerek Musk'ın ‘şirketi kâr amacı gütmeyen bir yapıdan kâr amaçlı yapıya dönüştürmek için çalmaya çalıştığı’ iddiasını reddetti. Altman ayrıca Musk'ın 2019'da şirketin ticari kolu kurma planına herhangi bir itirazda bulunmadığını ve SpaceX ile Tesla'nın başındaki ismin yönetim kurulundan ayrılmasından bir yıl önce bu plandan haberdar olduğunu vurguladı.
4 Mayıs’taki oturumda ise yazılım, bilgisayar mühendisliği ve AI profesörü Stuart Russell, bu alandaki denetimsiz yarışın riskleri hakkında ifade verdi. Yargıç Rogers, varoluşsal tehlikelere ilişkin açıklamalarını sınırlandırmasını istedi.
OpenAI CEO'su Sam Altman'ın Oakland kentindeki federal mahkemeye gelişi sırasında, 12 Mayıs 2026 (AFP)
5 ve 6 Mayıs oturumlarında Greg Brockman, şirketin kâr amaçlı modele geçişini savunduğu uzun bir savunma ifadesi verdi. 2017'de Musk ile yaşadığı gergin bir yüzleşmeyi aktaran Brockman, "Beni döveceğini sandım" dedi. Ayrıca Shivon Zilis'in Musk ile ilişkisinden ve onun şirket içinde "ajan ya da casus" rolü üstlendiği iddiasından söz etti. 6 Mayıs oturumunda ise eski OpenAI yönetim kurulu üyesi ve Musk'ın dört çocuğunun annesi olan Shivon Zilis, belirli güvenlik düzenlemeleri çerçevesinde hassas bir ifade verdi. Musk ile önceki romantik ilişkisini kabul eden Zilis, şirket içinde onun için sızıntı kaynağı işlevi gördüğü iddiasını reddetti.
Jürinin kararı
Dünya bu davanın jüri kararını bekliyor. Amerikan federal mahkeme hukukuna göre bu tür davalarda jürinin oybirliğiyle karar vermesi zorunlu; ancak bu sağlandığı takdirde Yargıç Rogers esasa ilişkin nihai hükmünü açıklayabilecek. Tek bir jüri üyesinin bile karşı çıkması durumunda ‘hung jury‘ (askıya alınmış jüri) hali ortaya çıkacak. Bu durum davanın yeni bir jüri heyeti önünde yeniden görülmesine yol açabilir. Böylece anlaşmazlık aylarca daha uzayabilir. Bu yüzden her iki tarafın da jüri üyelerini her türlü yolla ikna etmeye ve kendi safına çekmeye çalışması bekleniyor.
Duruşma sırasında Ronald V. Dellums Federal Binası'nın önünde Musk ve Altman'ın fotoğraflarının yapıştırıldığı şişme boks kuklalarının sergilendiği görüldü (AFP)
Davanın Musk lehine sonuçlanması halinde AI sistemlerinde açık kaynak modellerine kısmı bir dönüş yaşanabilir. Bu da üniversitelerin ve bağımsız araştırmacıların AI’ın gelişimini izlemesine ve sapmasını önlemesine olanak tanır. Altman'ın kazanması durumunda ise bu, büyük şirketlere insanlık tarihinin en büyük icadını ticari sır perdesi altında özelleştirme yolunu açan bir yeşil ışık olarak değerlendirilecek.
İnsanlık kritik bir kavşakta duruyor: Ya AI, kurucularının başlangıçta hayal ettiği gibi ‘insanlığın ortak mirası’ olarak kalacak ya da az sayıda güçlü şirketin tekelinde bir ‘teknolojik silaha’ dönüşecek.
Google, AI üretimli kritik güvenlik açığını tespit ettihttps://turkish.aawsat.com/teknoloji%CC%87/5272931-google-ai-%C3%BCretimli-kritik-g%C3%BCvenlik-a%C3%A7%C4%B1%C4%9F%C4%B1n%C4%B1-tespit-etti
Google, AI üretimli kritik güvenlik açığını tespit etti
Google Tehdit İstihbarat Grubu, yeni ve endişe verici yeni bir yapay zeka trendi tespit etti (Reuters)
Google'daki araştırmacılar, siber suçluların yapay zeka kullanarak en ciddi türdeki siber güvenlik açığını yarattığına dair ilk kanıtı bulduklarını açıkladı.
Google Tehdit İstihbarat Grubu'ndan (GTIG) bir ekip, siber suçluların sıfır-gün açığı diye bilinen bir güvenlik açığını keşfetmek için yapay zeka kullandığını bildirdi.
Yazılım geliştiricilerinin varlığından haberdar olmadığı, yani ona karşı korunma yolu bulmak için ellerinde sıfır gün olduğu bu tür açıklar bilhassa endişe veriyor.
Araştırmacılar pazartesi günü yayımlanan raporda, "GTIG, yapay zekayla geliştirildiğine inandığımız bir sıfır-gün istismarını kullanan bir tehdit aktörünü ilk kez tespit etti" diye yazdı.
Suçlu tehdit aktörü bunu kitlesel bir istismar olayında kullanmayı planlıyordu ancak proaktif karşı-keşfimiz bunun kullanımını önlemiş olabilir.
Araştırmacılar, Çin ve Kuzey Kore'yle bağlantılı hackerların sıfır-gün açıklarını bulmak için yapay zeka geliştirmeye "ciddi bir ilgi" gösterdiğini belirtti.
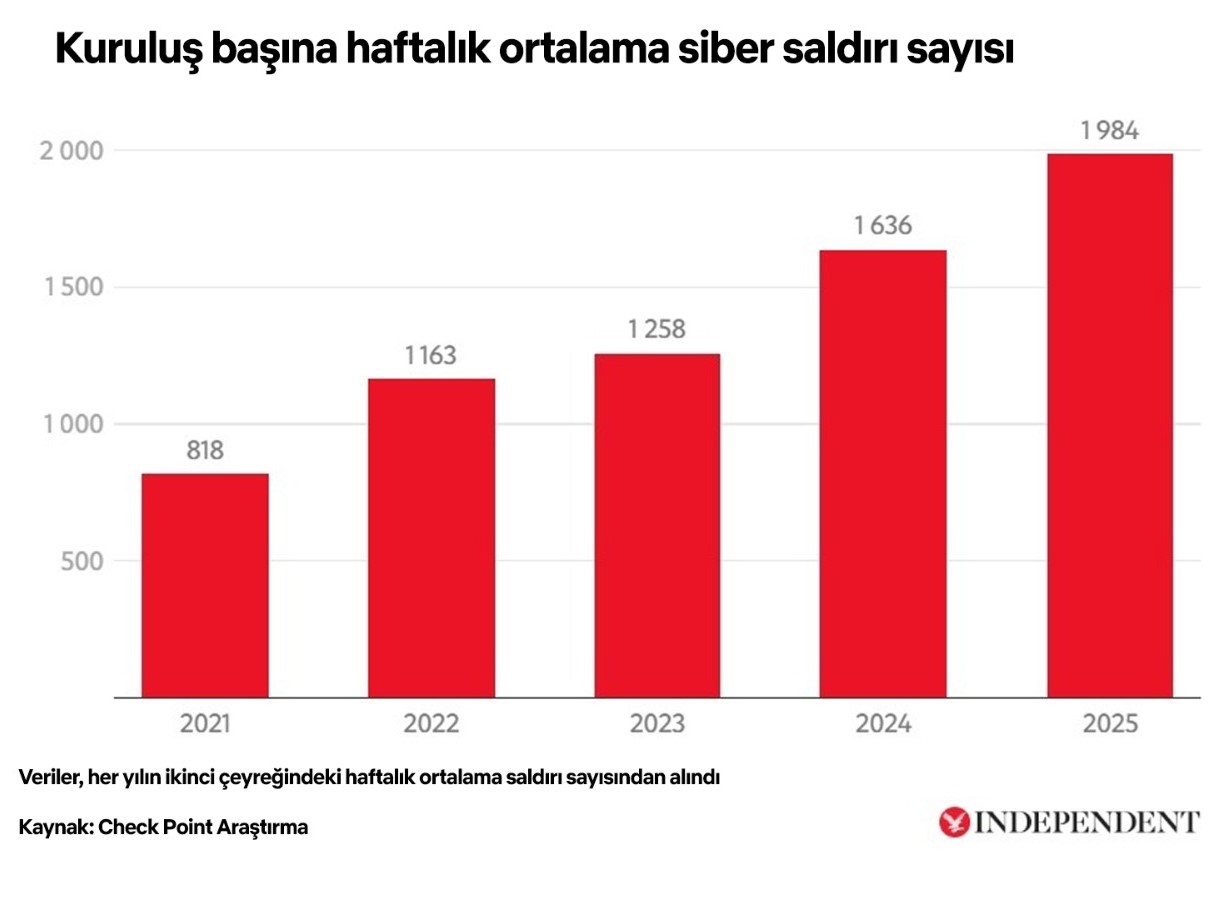
Siber suçluları cesaretlendiren yeni yapay zeka araçlarının ortaya çıkması, 2026'da rekor düzeyde siber saldırı gerçekleştirilmesine katkı sağladı.
Yakın zamanda yayımlanan bir raporda, yapay zeka bot saldırılarının son bir yılda 10 kattan fazla artarak küresel çapta 2 milyondan 25 milyona çıktığı tespit edilmişti.
Olaylardaki artış, Anthropic ve OpenAI gibi önde gelen yapay zeka şirketlerinin, güvenlik açıklarını herhangi bir insandan daha etkili bir şekilde tespit edebilen araçlar geliştirdiği dönemde yaşanıyor.
Anthropic'in kısa süre önce tanıttığı Mythos modeli, dünyanın tüm büyük işletim sistemleri ve internet tarayıcılarındaki yazılım açıklarını ortaya çıkardığı için "korkutucu bir süper hacker" diye tanımlanıyor.
Anthropic, yalnızca sınırlı sayıda teknoloji ve finans kuruluşuna sunulan modelin, bu kurumların siber savunmalarını güçlendirmeye katkı sağlayabileceğini iddia ediyor.
Google araştırmacıları, bu yeni modellerin potansiyel saldırılara karşı savunmaya yardımcı olabileceğini ancak siber suçluların bunları endişe verici ölçekte saldırılar gerçekleştirmek için suiistimal ettiğini belirtti.
Araştırmacılar son raporda, "Tehdit aktörleri kullanım sınırlarını yasadışı bir şekilde aşmak için artık profesyonelleştirilmiş ara yazılımlar ve otomatik kayıt işlem hatları aracılığıyla modellere anonim ve üst düzey erişim sağlamaya çalışıyor" uyarısında bulundu.
Bu altyapı, deneme sürümlerinin suiistimal edilmesi ve programlı hesap döngüleri yoluyla operasyonları finanse ederken, hizmetlerin büyük ölçekte kötüye kullanılmasını mümkün kılıyor.
Independent Türkçe
لم تشترك بعد
انشئ حساباً خاصاً بك لتحصل على أخبار مخصصة لك ولتتمتع بخاصية حفظ المقالات وتتلقى نشراتنا البريدية المتنوعة