Elektrikli otomobillerin yayalara çarpma ihtimalinin benzinlilerden fazla olduğu bulunduhttps://turkish.aawsat.com/teknoloji%CC%87/5023725-elektrikli-otomobillerin-yayalara-%C3%A7arpma-ihtimalinin-benzinlilerden-fazla-oldu%C4%9Fu
Elektrikli otomobillerin yayalara çarpma ihtimalinin benzinlilerden fazla olduğu bulundu
Bazı elektrikli otomobillerde, aracın sesini yükseltecek akustik cihazlar da kullanılıyor (Unsplash)
Birleşik Krallık'ta yapılan bir çalışmada, elektrikli otomobillerin yayalara çarpma ihtimalinin benzinli araçlara göre daha yüksek olduğu belirlendi.
Hakemli dergi Journal of Epidemiology and Community Health'de 21 Mayıs'ta yayımlanan araştırmada, Britanya'da 2013-2017'ye ait trafik kazası verileri incelendi. Bir arşiv sorunu nedeniyle 2018 sonrası verilerin değerlendirmeye alınamadğı aktarıldı.
Araştırmada, elektrikli ve hibrit araçlara dair 51,2 milyar kilometrelik, benzinli otomobillere dair de 4,8 milyar kilometrelik seyir verisi kullanıldı.
Çalışmada, elektrikli ve hibrit araçların yayalara çarpma ihtimalinin, fosil yakıtla çalışan araçlara göre kilometre başına iki kat daha fazla olduğu belirlendi.
Kırsal bölgelerde elektrikli araçların benzinli veya dizel araçlardan daha tehlikeli olmadığı fakat kasaba ve şehirlerde yayalarla çarpışma ihtimallerinin üç kat daha arttığı tespit edildi.
Kat edilen 106 kilometre başına yıllık ortalama yayalara çarpma oranı benzinli ve dizel araçlarda 2,4 iken elektrikli ve hibrit araçlarda 5,16 oldu.
Çalışmada, elektrikli araçların yayalara çarpma ihtimalinin benzinli araçlara göre daha yüksek olmasının sebebi net olarak belirlenemedi.
Fakat bilim insanları, bunun elektrikli ve hibrit araçların, içten yanmalı motora sahip otomobillere kıyasla daha sessiz olmasından kaynaklanabileceğine dikkat çekti.
Araştırmanın yazarlarından Phil Edwards, "Elektrikli arabalar yayalar için tehlike oluşturuyor çünkü benzinli ya da dizel arabalara kıyasla sesleri daha az duyuluyor" dedi.
London School of Hygiene and Tropical Medicine'nde çalışan akademisyen, şöyle devam etti:
Elektrikli otomobil alacaksanız, bunun yeni bir araç türü olduğunu unutmayın. Bilindik otomobillere kıyasla çok daha sessizler. Yayalar trafik seslerini dinleyerek hareket etmeye alışık. Dolayısıyla bu araçların sürücülerinin ekstra dikkatli olması gerekiyor.
ABD Ulaştırma Bakanlığı'nın 2017'de yayımladığı raporda da elektrikli ve hibrit otomobillerin benzinli ve dizel araçlara kıyasla yayalar için yüzde 20 daha fazla risk oluşturduğu aktarılmıştı.
Elektrikli ve hibrit araçların özellikle dönüş, geri vites, yola çıkma ve durma gibi düşük hızlı hareketler sırasında yayalar için yüzde 50 daha fazla risk oluşturduğu belirtilmişti.
Google, AI üretimli kritik güvenlik açığını tespit ettihttps://turkish.aawsat.com/teknoloji%CC%87/5272931-google-ai-%C3%BCretimli-kritik-g%C3%BCvenlik-a%C3%A7%C4%B1%C4%9F%C4%B1n%C4%B1-tespit-etti
Google, AI üretimli kritik güvenlik açığını tespit etti
Google Tehdit İstihbarat Grubu, yeni ve endişe verici yeni bir yapay zeka trendi tespit etti (Reuters)
Google'daki araştırmacılar, siber suçluların yapay zeka kullanarak en ciddi türdeki siber güvenlik açığını yarattığına dair ilk kanıtı bulduklarını açıkladı.
Google Tehdit İstihbarat Grubu'ndan (GTIG) bir ekip, siber suçluların sıfır-gün açığı diye bilinen bir güvenlik açığını keşfetmek için yapay zeka kullandığını bildirdi.
Yazılım geliştiricilerinin varlığından haberdar olmadığı, yani ona karşı korunma yolu bulmak için ellerinde sıfır gün olduğu bu tür açıklar bilhassa endişe veriyor.
Araştırmacılar pazartesi günü yayımlanan raporda, "GTIG, yapay zekayla geliştirildiğine inandığımız bir sıfır-gün istismarını kullanan bir tehdit aktörünü ilk kez tespit etti" diye yazdı.
Suçlu tehdit aktörü bunu kitlesel bir istismar olayında kullanmayı planlıyordu ancak proaktif karşı-keşfimiz bunun kullanımını önlemiş olabilir.
Araştırmacılar, Çin ve Kuzey Kore'yle bağlantılı hackerların sıfır-gün açıklarını bulmak için yapay zeka geliştirmeye "ciddi bir ilgi" gösterdiğini belirtti.
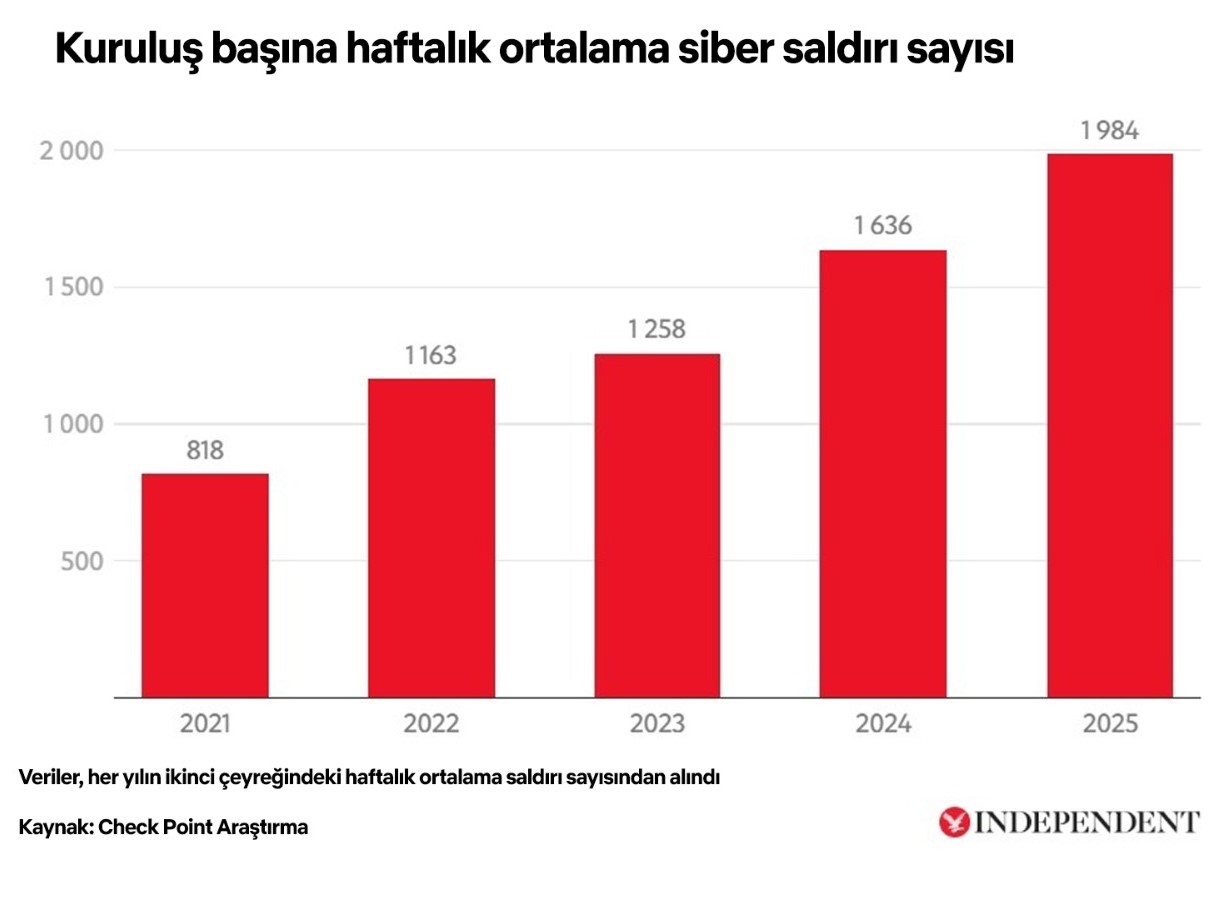
Siber suçluları cesaretlendiren yeni yapay zeka araçlarının ortaya çıkması, 2026'da rekor düzeyde siber saldırı gerçekleştirilmesine katkı sağladı.
Yakın zamanda yayımlanan bir raporda, yapay zeka bot saldırılarının son bir yılda 10 kattan fazla artarak küresel çapta 2 milyondan 25 milyona çıktığı tespit edilmişti.
Olaylardaki artış, Anthropic ve OpenAI gibi önde gelen yapay zeka şirketlerinin, güvenlik açıklarını herhangi bir insandan daha etkili bir şekilde tespit edebilen araçlar geliştirdiği dönemde yaşanıyor.
Anthropic'in kısa süre önce tanıttığı Mythos modeli, dünyanın tüm büyük işletim sistemleri ve internet tarayıcılarındaki yazılım açıklarını ortaya çıkardığı için "korkutucu bir süper hacker" diye tanımlanıyor.
Anthropic, yalnızca sınırlı sayıda teknoloji ve finans kuruluşuna sunulan modelin, bu kurumların siber savunmalarını güçlendirmeye katkı sağlayabileceğini iddia ediyor.
Google araştırmacıları, bu yeni modellerin potansiyel saldırılara karşı savunmaya yardımcı olabileceğini ancak siber suçluların bunları endişe verici ölçekte saldırılar gerçekleştirmek için suiistimal ettiğini belirtti.
Araştırmacılar son raporda, "Tehdit aktörleri kullanım sınırlarını yasadışı bir şekilde aşmak için artık profesyonelleştirilmiş ara yazılımlar ve otomatik kayıt işlem hatları aracılığıyla modellere anonim ve üst düzey erişim sağlamaya çalışıyor" uyarısında bulundu.
Bu altyapı, deneme sürümlerinin suiistimal edilmesi ve programlı hesap döngüleri yoluyla operasyonları finanse ederken, hizmetlerin büyük ölçekte kötüye kullanılmasını mümkün kılıyor.
Independent Türkçe
Lazer silahları... Geliştirme konusunda küresel bir yarışhttps://turkish.aawsat.com/teknoloji%CC%87/5272762-lazer-silahlar%C4%B1-geli%C5%9Ftirme-konusunda-k%C3%BCresel-bir-yar%C4%B1%C5%9F
Lazer silahları... Geliştirme konusunda küresel bir yarış
Lazer sistemleri giderek daha karmaşık hale geliyor
Geçtiğimiz eylül ayında, lazer silahları alanında dünyanın bir dönüm noktasına yaklaştığını yazmıştım. Bu değerlendirme, Çin’in Pekin’de düzenlenen bir askerî geçit töreninde LY-1 adlı deniz konuşlu lazer silahını tanıtmasının, ABD’nin lazerle donatılmış ilk muharebe araçlarını Amerikan ordusuna teslim etmesinin, Fransa’nın insansız hava araçlarına (İHA) karşı kullanılmak üzere yeni bir lazer prototipi talep etmesinin ve Hindistan’ın yönlendirilmiş enerji bileşeni içeren entegre hava savunma sistemini test etmesinin ardından gelmişti. Bu gelişmeleri Jared Keller da kaleme almıştı. Sonuç olarak şu nötr değerlendirmeye varmıştım: Küresel lazer silahları yarışının kazananı, teknolojik üstünlüğe kimin sahip olduğuyla değil, yönlendirilmiş enerji alanındaki hedeflerini gerçeğe dönüştürmek için gerekli siyasi iradeyi kimin göstereceğiyle belirlenecek.
Askeri lazer sistemleri
Askerî alanda lazer sistemlerinin kullanımına ilişkin çok sayıda rapor da giderek artıyor. Bunlar arasında İsrail’in yüksek enerjili lazer silahı Demir Işın (Iron Beam) öne çıkıyor; söz konusu sistemin 100 kilowatt güce sahip olduğu belirtiliyor. Diğer yandan The Defence Blog adlı internet sitesinde yer alan haberde, Çin yapımı bir lazer silahının havaalanı savunması amacıyla bir araca entegre edilmiş şekilde tespit edildiği bildirildi. Bu sistemin, ilk kez 2022 yılında Zhuhai kentinde gerçekleşen Çin Uluslararası Havacılık ve Uzay Fuarı’nda tanıtılan Guangjian-21A sistemiyle büyük ölçüde örtüştüğü ifade edildi.
Askeri gemide bulunan bir lazer silah sistemi
ABD ise düşük hızda, sabit konuşlu ve küçük boyutlu İHA’lara karşı geliştirilen lazer karşıtı sistemleri pazarlıyor. ABD Savunma Bakanlığı tarafından kullanılan bu sistemler Entegre İnsansız Hava Aracı İmha Sistemleri (FS-LIDS) olarak biliniyor. Böylece bugün lazer silahları alanındaki küresel yarış, giderek büyüyen rekabetçi bir pazara dönüşmüş durumda. Bu pazarda, rakip güçlere ait sistemler giderek aynı envanterlerde ve hatta aynı operasyon sahalarında birlikte varlık gösteriyor.
Hızlanan geliştirme süreci
Nisan ve mayıs ayları boyunca, lazer silahlarının küresel ölçekte gelişim hızı, o dönüm noktasına ilişkin analizimde görmediğim bir seviyeye ulaştı; hatta bu hızın artık daha da artmış olabileceği değerlendiriliyor.
Almanya ve Avustralya
* Geliştirme süreçleri – Almanya: Geçtiğimiz 10 Nisan’da Alman ordusu Bundeswehr, WTD 91 test sahasında (Meppen) yürütülen lazer silahı testlerine ilişkin bir rapor yayımladı. Raporda, farklı olgunluk seviyelerinde dört ayrı sistem detaylandırıldı. Bunlar arasında, Almanya-Hollanda ortak yapımı Jupiter sistemi de yer aldı; bu sistem Boxer muharebe aracına entegre edilmiş durumda. Ayrıca, 2029 yılına kadar operasyonel olarak konuşlandırılması planlanan Sachsen firkateyni üzerinde test edilen deneysel bir deniz platformu da raporda yer aldı.
* Avustralya planları: 21 Nisan’da Avustralya hükümeti, İHA’larla mücadele kabiliyetlerini güçlendirmek için yatırımlarını önümüzdeki on yılda 7 milyar dolara çıkarma planını açıkladı. Bu kapsamda, AIM Defence şirketine ait yüksek enerjili taşınabilir Fractl sisteminin geliştirilmesi için 21,3 milyon dolarlık başlangıç sözleşmesi imzalandı. Bir hafta sonra Avustralya Savunma Sanayii Bakanı Pat Conroy, Avustralya ordusunun 300 adet Bushmaster aracının yeni üretim partisinde lazer silahları entegre etmeyi planladığını duyurdu.
Çin ve Güney Kore
* Çin silahları: 22 Nisan’da Army Recognition adlı internet sitesi, Çinli Novasky Technology şirketinin 3 kilowatt gücündeki NI-L3K adlı lazer silahını Malezya’da düzenlenen Defence Services Asia 2026 savunma fuarında tanıttığını bildirdi. Kamyona monte edilen sistemin, özellikle İHA’lara karşı son savunma hattı olarak tasarlandığı ve ihracat amacıyla geliştirildiği belirtildi. Bu gelişme, Pekin’in yönlendirilmiş enerji silahları ticaretine artan şekilde dahil olmasıyla birlikte son haftalarda görülen ikinci benzer sistem oldu.
* Güney Kore planları: 24 Nisan’da Seoul Economic Daily, kaynaklara dayandırdığı haberinde Güney Kore’nin Cheongwang adlı 20 kilowatt gücündeki ikinci lazer silahını Seul yakınlarında konuşlandırmayı planladığını yazdı. Sistem, Kuzey Kore’ye ait İHA’ları düşürmeyi hedefliyor. Ayrıca yetkililerin, 2027 yılına kadar nükleer santraller, havaalanları ve limanlar gibi kritik altyapıyı kapsayacak şekilde savunma ağının genişletilmesini hızlandırmayı planladığı aktarıldı.
Rusya ve Türkiye
* Rusya hava savunma sistemleri: 1 Mayıs’ta Rusya’nın resmi haber ajansı TASS, hükümetin İHA’lara karşı lazer silahlarını ülkenin hava sahası sınırlarını koruyan operasyonel sistemler arasına dahil eden bir kararname yayımladığını bildirdi. Rus lazer silahlarının kapasitesine ilişkin doğrulanmış veriler ile propaganda iddiaları arasındaki belirsizlik sürerken, söz konusu kararın Moskova’nın bu sistemleri ‘deneysel’ aşamadan ‘aktif kullanım’ kategorisine taşıdığına işaret ettiği değerlendiriliyor.
* Türk lazer silahları: 5 Mayıs’ta Türkiye, yeni lazer silahlarını İstanbul’da düzenlenen SAHA 2026 savunma fuarında tanıttı. ASELSAN tarafından geliştirilen 10 kilowatt gücündeki GÖKBERK 10 ile TÜBİTAK üretimi 20 kilowatt gücündeki YGLS sistemleri (80 kilowatta kadar ölçeklenebilir olduğu belirtiliyor) öne çıktı. Her iki sistemin de ülkenin Çelik Kubbe konseptine katkı sağladığı, bu konseptin ise füze sistemleri, radar, elektronik harp ve yönlendirilmiş enerji unsurlarını tek bir ulusal hava savunma ağı altında birleştirmeyi hedefleyen entegre bir komuta-kontrol yapısı öngördüğü ifade edildi.
Amerikan lazer kubbesi
Şarku’l Avsat’ın edindiği bilgilere 6 Mayıs’ta ABD, Savunma Bakanlığı’na (Pentagon) bağlı Ortak Kurumlar Arası Görev Gücü 401’in İHA’larına karşı yönlendirilmiş enerji kullanımıyla mücadeleye yönelik bir pilot program için beş askerî tesis seçtiğini açıkladı. Bu adım, stratejik varlıklar ve kritik altyapının korunmasına yönelik ‘lazer kalkanı’ benzeri bir ulusal savunma konseptinin oluşturulması yolunda önemli bir aşama olarak değerlendiriliyor. Operasyonların, tesis komutanlarıyla birlikte yürütülecek konuşlanma planlarının 180 gün içinde tamamlanmasının ardından, yılın ilerleyen dönemlerinde başlaması bekleniyor.
Ukrayna’nın lazer kompleksi
7 Mayıs’ta Ukraynalı şirket Celera Tech, Tryzub adlı lazer kompleksinin mobil bir platforma, römorka monte edilecek şekilde entegre edildiğini ve nihai testlerin ardından kamuoyuna tanıtılmak üzere hazırlandığını açıkladı. Sistem ilk kez 2024 yılında Ukrayna’nın İnsansız Sistemler Kuvvetleri Komutanı tarafından kamuoyuna duyurulmuş, 2025 yılında ise sergilenmişti. Şirketin açıklamasına göre sistemin etkin menzili keşif amaçlı İHA’lara karşı bin 500 metreye (0,9 mil), FPV tipi İHA’lara karşı ise 800 ila 900 metreye (0,5 mil) ulaşıyor. Ayrıca sistemin, Şahid tipi İHA’lara karşı 5 kilometreye (3,1 mil) kadar etkili olduğu iddia ediliyor. En son geliştirme aşamasında ise yapay zekâ destekli hedefleme ve radar entegrasyonunun sisteme dahil edildiği belirtildi.
Sert eleştiriler alan Apple tasarım değişikliğine gidiyorhttps://turkish.aawsat.com/teknoloji%CC%87/5272568-sert-ele%C5%9Ftiriler-alan-apple-tasar%C4%B1m-de%C4%9Fi%C5%9Fikli%C4%9Fine-gidiyor
Sert eleştiriler alan Apple tasarım değişikliğine gidiyor
20 Eylül 2024'te New York'taki Apple Store'da düzenlenen lansman sırasında sergilenen Apple iPhone 16 telefonları (AFP)
Yeni haberlere göre Apple, işletim sisteminin tartışmalı yeni görünümünde bazı küçük değişiklikler yapmaya hazırlanıyor ancak bu tasarımdan tamamen vazgeçmeyecek.
Eylülde yeni iPhone 17 modelleriyle birlikte Apple, cihazlarında çalışan tüm yazılımlar için yeni bir görünüm olan "Sıvı Cam"ı tanıtmıştı.
Apple, bunun cihazlarının tek parça camdan oluştuğu fikrini yansıtmak ve insanların izledikleri içeriğe odaklanmasını sağlamak için tasarlandığını söylemişti. Ancak tasarımı eleştirenler, telefon kullanımını zorlaştırdığı ve önemli bilgileri gizlediği gerekçesiyle değişikliği sert biçimde eleştirmişti.
Apple daha sonra kullanıcılara en çok tartışılan şeffaflık efektlerinden bazılarını kapatma seçeneği sunmak da dahil olmak üzere tasarımda bir dizi küçük değişiklik yaptı. Ayrıca, değişikliğe öncülük eden ve kamuoyuna duyuran tasarımcı Alan Dye da şirketten ayrıldı.
Bu durum şirketin güncellemeyi tamamen terk etmeyi veya görünümünde önemli değişiklikler yapmayı planladığı yönünde bazı spekülasyonlara yol açtı.
Şimdiyse yeni bir habere göre Apple, iPhone'un görünümünde değişiklikler yapacak. Ancak Apple'daki değişiklikleri kamuoyuna açıklanmadan önce haberleştirme konusunda güçlü bir sicili olan Bloomberg'den Mark Gurman'a göre, değişiklikler özellikle yeni görünümün "gölge ve şeffaflıkla" ilgili pürüzlere odaklanacak.
Gurman, değişikliklerin özellikle macOS'ta yeni görünümün uygulanmasına odaklanacağını bildirdi. Bu sorunlar, Mac'lerin daha büyük ekranlarında belirgin olduğu için özellikle eleştirilmişti.
Gurman, bu eleştirilerin bir kısmının, Apple'ın yeni görünümü iPhone ve diğer Apple cihazlarındaki OLED ekranlarda kullanılmak üzere tasarlamış olmasından kaynaklanabileceğini öne sürdü. MacBook'larda henüz bu ekran teknolojisi yok ancak yakında piyasaya sürülmesi bekleniyor.
Gurman, yeni görünümün dışında Apple'ın yazılımının sonraki sürümleri için performans ve pil iyileştirmeleri üzerinde çalıştığını da bildirdi. Ayrıca Apple'ın yıllardır yeni yapay zeka teknolojisiyle geliştirmeyi vaat ettiği ancak henüz piyasaya sürülmemiş olan Siri'nin güncellenmiş bir sürümünü de getirmesi bekleniyor.
Apple'ın, tüm yeni değişiklikleri 8 Haziran'da yapılması planlanan yıllık yazılım etkinliği Dünya Geliştiriciler Konferansı'nda açıklaması bekleniyor.
Independent Türkçe
لم تشترك بعد
انشئ حساباً خاصاً بك لتحصل على أخبار مخصصة لك ولتتمتع بخاصية حفظ المقالات وتتلقى نشراتنا البريدية المتنوعة